기본 환경: IDE: VS code , Language: Python
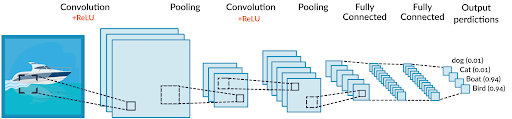
CNN(Convolution Neural Network, 합성곱 신경망)
: 영상처리에 많이 활용되는 합성곱을 사용하는 신경망 구조
기존처럼 데이터에서 지식을 추출해 학습하는 것이 아니라 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조
Conv2D with Maxpooling
# cnn_conv2D_maxPooling2D.py
import numpy as np
from tensorflow.keras.datasets import mnist, cifar10, cifar100
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D
# Maxpooling: 연산이 아니기때문에 model pkg가 아닌 layers pkg에 삽입, 2D: 이미지
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
'''
x_train.shape: (60000, 28, 28) # 행(28), 열(28), 흑백(1-생략)인 이미지 데이터 60000개
y_train.shape: (60000,) # 이미지에 대한 값을 수치화
'''
# CNN Conv2D 처리하기 위해 4D(Tensor)화
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
'''
# y_train에서 동일한 값의 빈도수 반환
print(np.unique(y_train, return_counts=True))
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), # y_calss
array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949], dtype=int64) y_class의 개수)
'''
# 2. Model
model = Sequential()
model.add(Conv2D(filters=128,
kernel_size=(3, 3),
strides=1,
padding='same',
input_shape=(28, 28, 1),
activation='relu'))
'''
padding=valid
output_shape=(26,26,128)
# output shape = input_shape - kernel_size +1 (Not using padding)
padding=same
output_shape=(28,28,128)
'''
model.add(MaxPooling2D())
# output_shape=(14, 14, 128)
# Parameter=0 (연산 X)
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
padding='same'))
# Sequential Model output->input이므로 입력값 작성 생략
model.add(Conv2D(filters=64,
kernel_size=(3, 3),
padding='same'))
model.add(MaxPooling2D())
model.add(Conv2D(filters=32,
kernel_size=(3, 3),
padding='same'))
model.add(Flatten()) # input_dim=7*7*32 (column)
model.add(Dense(32, activation='relu'))
# batch_size(총 훈련 필요 대상)=60000
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax')) # y_class=10
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 128) 1280
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
conv2d_1 (Conv2D) (None, 14, 14, 64) 73792
conv2d_2 (Conv2D) (None, 14, 14, 64) 36928
max_pooling2d_1 (MaxPooling2D) (None, 7, 7, 64) 0
conv2d_3 (Conv2D) (None, 7, 7, 32) 18464
flatten (Flatten) (None, 1568) 0
dense (Dense) (None, 32) 50208 = 1568*32 + 32
dropout (Dropout) (None, 32) 0
dense_1 (Dense) (None, 10) 330
=================================================================
Total params: 181,002
Trainable params: 181,002
Non-trainable params: 0
_________________________________________________________________
'''
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
# one-hot encoding 안했으므로, sparse_categorical_crossentropy
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath='cnn_conv2D_maxPooling2D.hdf5')
model.fit(x_train, y_train, epochs=256, batch_size=128,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path+'cnn_conv2D_maxPooling2D_save_model.h5')
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result
loss: 0.049012500792741776
acc: 0.9872999787330627
'''
⭐ Conv2D와 MaxPooling2D 차이
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# CNN Conv2D 처리하기 위해 4D(Tensor)화
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
# 2. Model
model = Sequential()
model.add(Conv2D(filters=128,
kernel_size=(3, 3),
padding='same',
strides=1,
input_shape=(28, 28, 1),
activation='relu'))
model.add(MaxPooling2D(pool_size=(5, 5)))
model.summary()
'''
Model: "sequential()"
______________________________________
Layer (type) Output Shape
======================================
(Conv2D) (None, 26, 26, 128) -> stride: defualt=1, 자르고 난 나머지 연산 대상에 포함
(MaxPooling2D) (None, 5, 5, 128) -> stride: default=kernel_size(겹치지 않게 진행), 자르고 난 나머지 연산 대상에 미포함
'''1. 잔여 Data 처리
2. Strides Default
CNN → DNN
1. reshape → DNN
# dnn_with_cnn_data1.py
import numpy as np
from tensorflow.keras.datasets import mnist, cifar10, cifar100, fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
'''
x_train.shape: (60000, 784), x_train.shape: (60000,)
x_test.shape: (10000, 784), x_test.shape: (10000,)
'''
# DNN Model을 위한 작업
# Flatten이 아닌 reshape을 통해서 2차원으로 변경
x_train = x_train.reshape(60000, 28*28)
x_test = x_test.reshape(10000, 28*28)
x_train=x_train/255.
x_test=x_test/255.
# 2. Model
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(784,)))
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='linear'))
model.add(Dense(10, activation='softmax'))
model.summary()
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath='dnn_with_cnn_data1_MCP.hdf5')
model.fit(x_train, y_train, epochs=256, batch_size=32,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path+'dnn_with_cnn_data1_save_model.h5')
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result(CNN)
loss: 0.16121244430541992
acc: 0.9692999720573425
Result(DNN)
loss: 0.08280020207166672
acc: 0.9758999943733215
'''
2. Flatten
# dnn_with_cnn_data2.py
import numpy as np
from tensorflow.keras.datasets import mnist, cifar10, cifar100, fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
'''
x_train.shape: (60000, 28, 28), x_train.shape: (60000,)
x_test.shape: (10000, 28, 28), x_test.shape: (10000,)
'''
x_train=x_train/255.
x_test=x_test/255.
# 2. Model
model = Sequential()
model.add(Flatten()) # 모델 초반부에 Flatten을 통한 1차원 배열로 변환 input_dim=28*28*1=784 (column)
# 차원: []의 개수
model.add(Dense(128, activation='relu', input_shape=(784,)))
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='linear'))
model.add(Dense(10, activation='softmax'))
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath='dnn_with_cnn_data2_MCP.hdf5')
model.fit(x_train, y_train, epochs=256, batch_size=32,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path+'dnn_with_cnn_data2_save_model.h5')
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result(CNN)
loss: 0.16121244430541992
acc: 0.9692999720573425
Result(DNN)
loss: 0.08222146332263947
acc: 0.977400004863739
'''
3. Dense → Flatten
# dnn_with_dnn_data3.py
import numpy as np
from tensorflow.keras.datasets import mnist, cifar10, cifar100, fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D # 2D: 이미지
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
'''
x_train.shape: (60000, 28, 28), x_train.shape: (60000,)
x_test.shape: (10000, 28, 28), x_test.shape: (10000,)
'''
x_train=x_train/255.
x_test=x_test/255.
# 2. Model
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(28,28)))
# (data_num, 28), input_dim=28
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='linear'))
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
model.summary()
'''
# Dense Model은 2차원 이상을 input으로 받는 것이 가능
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 28, 128) 3712
# output_layer = conv2D filter
dense_1 (Dense) (None, 28, 64) 8256
dense_2 (Dense) (None, 28, 32) 2080
flatten (Flatten) (None, 896) 0
dense_3 (Dense) (None, 10) 8970
=================================================================
Total params: 23,018
Trainable params: 23,018
Non-trainable params: 0
_________________________________________________________________
'''
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath='dnn_with_cnn_data3_MCP.hdf5')
model.fit(x_train, y_train, epochs=256, batch_size=32,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path+'dnn_with_cnn_data3_save_model.h5')
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result(CNN)
loss: 0.16121244430541992
acc: 0.9692999720573425
Result(DNN)
loss: 0.10574663430452347
acc: 0.9707000255584717
'''
➕ CNN Functional Model
# functional_model_with_cnn.py
import numpy as np
from tensorflow.keras.datasets import mnist, cifar10, cifar100, fashion_mnist
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D, Input
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. data
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# print(x_train.shape, y_train.shape) # (60000, 28, 28) (60000,)
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
x_train=x_train/255.
x_test=x_test/255.
# 2. Model
input1 = Input(shape=(28,28,1))
dense1 = Conv2D(filters=128,
kernel_size=(3, 3),
padding='same',
strides=1,
input_shape=(28, 28, 1),
activation='relu')(input1)
dense2 = MaxPooling2D()(dense1)
dense3 = Conv2D(filters=64,
kernel_size=(3, 3),
padding='same')(dense2)
dense4 = MaxPooling2D()(dense3)
dense5 = Conv2D(filters=32,
kernel_size=(3, 3),
padding='same')(dense4)
dense6 = Flatten()(dense5)
dense7 = Dense(32, activation='relu')(dense6)
output1 = Dense(10, activation='softmax')(dense7)
model = Model(inputs=input1, outputs=output1)
model.summary()
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath=path+'functional_model_with_cnn_MCP.hdf5')
model.fit(x_train, y_train, epochs=256, batch_size=64,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path+'functional_model_with_cnn_save_model.h5')
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result
loss: 0.2593150734901428
acc: 0.9047999978065491
'''
➕ DNN 데이터의 CNN 처리
# dnn_with_cnn_data_kaggle_bike.py
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential, Model, load_model
from tensorflow.keras.layers import Dense, Input, Dropout, Conv2D, Flatten, MaxPooling2D
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
path2 = './_save/'
# 1. Data
path = './_data/bike/'
train_csv = pd.read_csv(path+'train.csv', index_col=0)
test_csv = pd.read_csv(path+'test.csv', index_col=0)
submission = pd.read_csv(path+'sampleSubmission.csv', index_col=0)
train_csv = train_csv.dropna()
x = train_csv.drop(['casual', 'registered', 'count'], axis=1)
y = train_csv['count']
x_train, x_test, y_train, y_test = train_test_split(
x, y,
shuffle=True,
train_size=0.7,
random_state=123
)
# scaler = StandardScaler()
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
test_csv = scaler.transform(test_csv)
print(x_train.shape, x_test.shape)
print(test_csv.shape) # (6493, 8)
x_train = x_train.reshape(7620, 4, 2, 1)
x_test = x_test.reshape(3266, 4, 2, 1)
# 2. Model(Sequential)
model = Sequential()
model.add(Conv2D(128, (2,2), padding='same', activation='relu', input_shape=(4,2,1)))
model.add(MaxPooling2D(pool_size=(2, 1)))
model.add(Conv2D(64, (2,2), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 1)))
model.add(Conv2D(32, (2,2), padding='same', activation='relu'))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1)) # 분류모델이 아니므로 끝이 softmax가 아니어도 됨
model.summary()
'''
# 2. Model(Function)
input1 = Input(shape=(13,))
dense1 = Dense(64, activation='relu')(input1)
drop1 = Dropout(0.3)(dense1)
dense2 = Dense(64, activation='sigmoid')(drop1)
drop2 = Dropout(0.2)(dense2)
dense3 = Dense(32, activation='relu')(drop2)
drop3 = Dropout(0.15)(dense3)
dense4 = Dense(32, activation='linear')(drop3)
output1 = Dense(1, activation='linear')(dense4)
model = Model(inputs=input1, outputs=output1)
model.summary()
summray
node를 random하게 추출하여 훈련을 수행 -> 과적합 문제 해결
summary는 dropout된 node를 나누지 않음
predict 시에는 dropout 사용 X
Total params: 8,225
Trainable params: 8,225
Non-trainable params: 0
'''
# 3. compile and train
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32,
restore_best_weights=True,
verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath='MCP/keras39_5_kaggle_bike_MCP.hdf5')
model.fit(x_train, y_train,
epochs=256,
batch_size=64,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
model.save(path2+'keras39_5_kaggle_bike_save_model.h5') # 가중치 및 모델 세이브
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
def RMSE (y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE: ", RMSE(y_test, y_predict))
r2 = r2_score(y_test, y_predict)
print("R2: ", r2)
# for submission
test_csv = test_csv.reshape(6493, 4, 2, 1)
y_submit = model.predict(test_csv)
submission['count'] = y_submit
submission.to_csv(path+'sampleSubmission_0126.csv')
'''
Result(DNN)
RMSE: 150.45157752219103
R2: 0.30323941332889803
* 이미지가 아닌 데이터는 CNN이 좋은가 DNN이 좋은가
Result(CNN)
RMSE: 151.84623477201092
R2: 0.2902618673099654
'''1. Conv2D의 input_shape= 4차원이므로 data의 reshape 필요
x_train.shape(7620, 8) -> x_train.reshape(7620, 4, 2, 1)
데이터 수를 의미하는 7260을 제외한 8을 3차원으로 임의 변경 가능
2. input_shape보다 Conv2D(kernel_size), MaxPooling(Pool_size)가 커지지 않도록 shape 확인
model.add(Conv2D(128, (2,2), padding='same', activation='relu', input_shape=(4,2,1)))
input_shape=(4,2,1) -> 4*2 크기의 이미지, kernel_size=(3,3) 불가
3. traing data와 predict data shape 맞추기
traing data를 기준으로 model이 구성되었으므로 predict data shape도 traing data에 맞추기
소스 코드
🔗 HJ0216/TIL
참고 자료
📑 CNN Model Contruction