
기본 환경: IDE: VS code, Language: Python
CNN(Convolution Neural Network, 합성곱 신경망)
: 영상처리에 많이 활용되는 합성곱을 사용하는 신경망 구조
기존처럼 데이터에서 지식을 추출해 학습하는 것이 아니라 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조
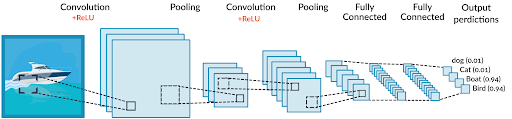
CNN 학습 과정
0(y) = imageA (x)
1. colvolution 과정을 통해 특성맵 추출
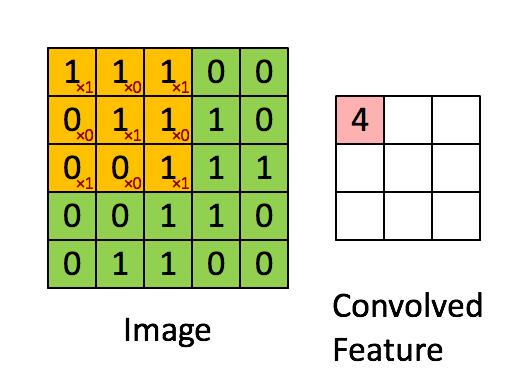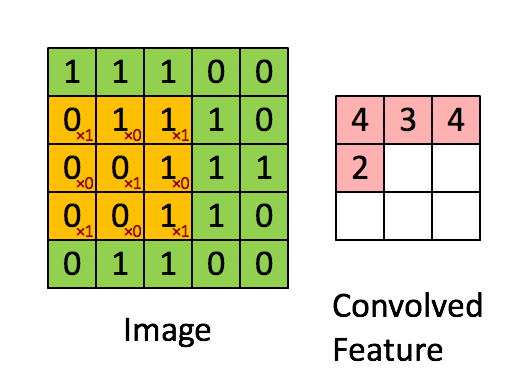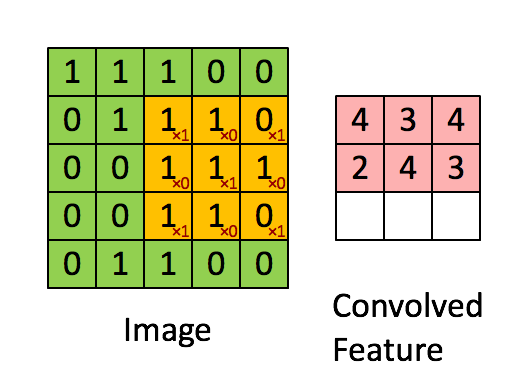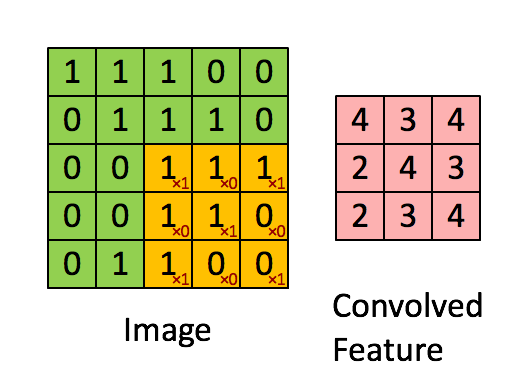
➕ 필요할 경우, 패딩(Padding, 결과 값 행렬의 크기를 조정하기 위해 입력 배열의 둘레를 확장하고 0으로 채우는 연산) 진행
2. Pooling 과정을 통해 데이터의 특성 강조
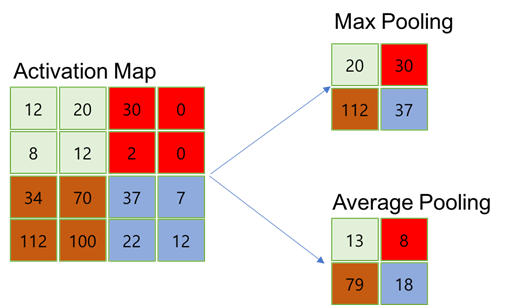
풀링(Pooling): 일정 크기의 블록을 통합하여 하나의 대표값으로 대체하는 연산으로 컨볼루션 층에서 출력된 특징 지도를 압축하여 특정 데이터를 강조하는 역할
3. Conv와 Pooling의 반복 연산을 통해 입력 이미지 배열을 특징들만을 포함한 하나의 1차원 배열 데이터로 변환
4. 다층 퍼셉트론 층(Fully Connected Layer)을 통한 연산 수행 및 회귀 혹은 분류 진행
CNN 기본 모델 Summary
# conv2D_model_summary
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten
# 이미지 = 2차원(2D) -> Conv2D 사용
model = Sequential()
# 입력: 데이터개수(무시), 가로(5), 세로(5), 색깔(1 or 3)
# 데이터의 개수는 중요하지 않으므로 (NaN, 5, 5, 1)
model.add(Conv2D(filters=10, kernel_size=(2,2),
input_shape=(5,5,1)))
# 이미지 픽셀 수(5*5) 1개(흑백) 3개(컬러RPG)
# kernel_size = 합을 연산할 이미지 블럭의 사이즈(2*2)
# 1 layer 연산 후 5*5 -> 4*4 -> ... 연산량이 점점 줄어감
# filter = 10: 5*5 흑백 이미지 1장을 10장으로 늘림
# hyper-parameter tuning: filters, kernel_size, activation 등
model.add(Conv2D(5, (2,2))) # model.add(Conv2D(filters=5, kernel_size=(2,2)))
# 2번째 conv2D는 1번째 모델의 output(4*4*10)
# filter = 5: 4*4(블럭화 후 이미지 크기가 줄어듬) 흑백 이미지 1장을 5장을 쌓아둠
# filter: Dense의 hidden output layer
# 이미지를 수치화하기 위해 column을 class화 하여 y값과 연결: Conv2D->Flatten
model.add(Flatten()) # (3*3*5) -> (45, ) (Nan, 45)
# column화 시키기(3*3*5=45): 45개의 특성(Column)을 갖는 n개의 이미지로 DNN 교육
model.add(Dense(units=10))
# (임의) hidden 10 layer 처리
model.add(Dense(1)) # 이미지의 최종 수치화, (Nan, 1)
# Nan = 고정적으로 제공되는 Data의 양
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 4, 4, 10) 50
연산에 따라 사이즈가 줄어감
conv2d_1 (Conv2D) (None, 3, 3, 5) 205
5 = filter 수
-------------------------------DNN---------------------------------
flatten (Flatten) (None, 45) 0 (flatten은 펴주는 것이므로 연산량 X)
dense (Dense) (None, 10) 460 (bias +1)
dense_1 (Dense) (None, 1) 11
=================================================================
Conv2D parm 연산법
Param #
Conv2D 1번째: 필터 크기(kernel_size)*입력 채널(color)*출력 채널(filter)+출력 채널의 bias(filter)
-> (2*2) * 1 * 10 + 10
Conv2D 2번째: 필터 크기(kernel_size)*입력 채널(이전 filter)*출력 채널(filter)+출력 채널의 bias(filter)
-> (2*2) * 10 * 5 + 5
'''
'''
Conv2D Input_shape(rows, cols, channels)
1. rows: 행
2. columns: 열
3. channnels: color(흑백-1, 컬러-3)
-> data 개수가 x개 일 때,
(x, rows, cols, channels) 표기하는 것이 맞지만 데이터 수는 결정되어있는 상태이므로 (rows, cols, channels)로 표시
Dense Input_shape(None, cols)
-> data 개수가 x개 일 때,
(x, cols) 표기하는 것이 맞지만 데이터 수는 결정되어있는 상태이므로 (cols,)로 표시
'''
➕ Conv2D()와 Desne() Layer 정의
#Conv2D
'''
def __init__(self,
filters, # 합성곱에 사용되는 필터의 개수
kernel_size, # 합성곱에 사용되는 필터의 크기
strides=(1, 1), # 풀링 필터를 이동시키는 간격, 지정해주지 않을 경우(None)에 오버랩없이 풀링 진행
padding='valid', # conv 후 이미지 크기 유지시킬 것인지 유무
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=None, # 활성화 함수
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs): # keyword args의 줄임말
'''
#Dense
'''
def __init__(self,
units, # 다음에 전달될 layer
activation=None, # 활성화 함수
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
'''
1. Mnist dataset CNN model construction
# cnn_mnist.py
import numpy as np
import datetime
from tensorflow.keras.datasets import mnist
# mnist: 고등학생과 미국 인구조사국 직원들이 손으로 쓴 70,000개의 작은 숫자 이미지들의 집합
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
filepath = './_save/MCP/'
filename = '{epoch:04d}-{val_loss:.4f}.hdf5'
# 04d: 10진수 빈자리 0 표시
# .4f: 소수점 4번째자리까지 표시
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
# (60000, 28, 28) (60000,)
# 행(28), 열(28), 흑백(1-생략)인 이미지 데이터 60000개
# scalar=1인 데이터 60000개
print(x_test.shape, y_test.shape)
'''
reshpae
CNN Conv2D 처리하기 위해 4D(Tensor)화
(60000, 28, 28) -> (60000, 28, 28, 1)
'''
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
# train, test 분리되어있으므로 split 필요 X
print(np.unique(y_train, return_counts=True))
'''
y_train 다중 분류인지 데이터 특성 파악
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), # y_calss
array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949], dtype=int64) y_class의 개수)
'''
'''
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
ValueError: Found array with dim 4.
StandardScaler expected <= 2.
StandardScaler, MinMaxScaler는 dim=2인 경우에 가능
'''
# 2. Model
model = Sequential()
model.add(Conv2D(filters=128,
kernel_size=(2, 2),
input_shape=(28, 28, 1),
activation='relu')) # Conv2D 후, result (27, 27, 128)
model.add(Conv2D(filters=64,
kernel_size=(2, 2))) # Conv2D 후, result (26, 26, 64)
model.add(Conv2D(filters=64,
kernel_size=(2, 2))) # Conv2D 후, result (25, 25, 64)
model.add(Flatten()) # input_dim=25*25*64=40000 = column
model.add(Dense(32, activation='relu')) # 32- 임의
# 60000=batch_size(총 훈련 필요 대상), 40000=input_dim
model.add(Dropout(0.3))
model.add(Dense(10, activation='softmax')) # 10=y_class
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
# one-hot encoding 안했으므로, sparse
# one-hot encoding 후 (60000, 10=y_class)
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
date = datetime.datetime.now()
date = date.strftime("%m%d_%H%M") #mmdd_hhmm
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath=filepath + 'cnn_mnist_' + date + '_' + filename)
model.fit(x_train, y_train, epochs=64, batch_size=512,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result
loss: 0.16762535274028778
acc: 0.9696000218391418
'''
2. Cifar10 dataset CNN model construction
# cnn_cifar10.py
import datetime
import numpy as np
from tensorflow.keras.datasets import cifar10, cifar100
# cifar10: 총 10개의 label, label 당 6000개의 이미지로 이뤄진 data set
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout, MaxPooling2D
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
filepath = './_save/MCP/'
filename = '{epoch:04d}-{val_loss:.4f}.hdf5'
# 1. data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print(x_train.shape, y_train.shape) # (50000, 32, 32, 3) (50000, 1)
print(x_test.shape, y_test.shape) # (10000, 32, 32, 3) (10000, 1)
# pixel값의 최대 수치인 255로 직접 나눠주어 정규화 scaling
x_train = x_train/255
x_test = x_test/255
print(np.unique(y_train, return_counts=True))
'''
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000], dtype=int64))
'''
# 2. Model
model = Sequential()
model.add(Conv2D(filters=128,
kernel_size=(2, 2),
padding='same',
input_shape=(32, 32, 3),
activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(filters=64,
kernel_size=(2, 2),
padding='same',
activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(filters=64,
kernel_size=(2, 2),
padding='same',
activation='relu'))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
# dropout = rate: Float between 0 and 1. Fraction of the input units to drop.
# 사용하지 않을 node의 비율
model.add(Dense(10, activation='softmax'))
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
date = datetime.datetime.now()
date = date.strftime("%m%d_%H%M")
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath=filepath + 'cnn_cifar10_' + date + '_' + filename)
model.fit(x_train, y_train, epochs=256, batch_size=128,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
# 4. evaluate and predict
result = model.evaluate(x_test, y_test)
print("loss: ", result[0])
print("acc: ", result[1])
'''
Result
loss: 0.9623041749000549
acc: 0.6858000159263611
'''
➕ MinMaxScaler, StandardScaler Dimension Error 해결
# cnn_mnist_scaler.py
import numpy as np
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.datasets import mnist, cifar10, cifar100
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# 1. data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# x_train.shape: (60000, 28, 28)
# x_test.shape: (10000, 28, 28)
print(x_train.shape, x_test.shape)
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
'''
ValueError: Found array with dim 4.
StandardScaler expected <= 2.
StandardScaler, MinMaxScaler는 dim=2인 경우에 가능
'''
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
# dimension을 변경했을 경우, 내부적인 수치는 성능에 따라 변경 가능
# (60000, 784) -> (60000, 28, 28, 1) O (60000, 14, 56, 1) O ...
➕ CNN Model과 HyperParameterTuning
# 2. Model
model = Sequential()
model.add(Conv2D(filters=128,
kernel_size=(3, 3),
strides=1,
padding='same',
input_shape=(28, 28, 1),
activation='relu'))
'''
# padding
padding=valid
output_shape=(26,26,128)
output shape = input_shape - kernel_size +1 (Not using padding)
padding=same
output_shape=(28,28,128)
'''1. filters: 훈련할 이미지의 개수
2. kernel_size: feature map 크기 결정
3. strides: data 중복 관리
4. padding opt: data 손실 관리
5. activation: 모델의 표현력 향상, 모델의 비선형성
소스 코드
참고 자료
📑 딥러닝 #2 (CNN 구조, CNN 학습 알고리즘)
'Naver Clould with BitCamp > Aartificial Intelligence' 카테고리의 다른 글
| CNN Model Construction2 (0) | 2023.01.26 |
|---|---|
| Save model and weights (0) | 2023.01.24 |
| Data Preprocessing: StandardScaler, MinMaxScaler (0) | 2023.01.23 |
| Classification Model Construction (0) | 2023.01.23 |
| Pandas pkg and Numpy pkg (1) | 2023.01.23 |