프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
📝 Language: Oracle
|
1
2
3
4
5
6
7
8
9
|
SELECT O.ANIMAL_ID,
O.NAME
FROM ANIMAL_OUTS O
FULL JOIN ANIMAL_INS I
ON O.ANIMAL_ID = I.ANIMAL_ID
WHERE I.ANIMAL_ID IS NULL
ORDER BY O.ANIMAL_ID
;
|
Full outer join 사용
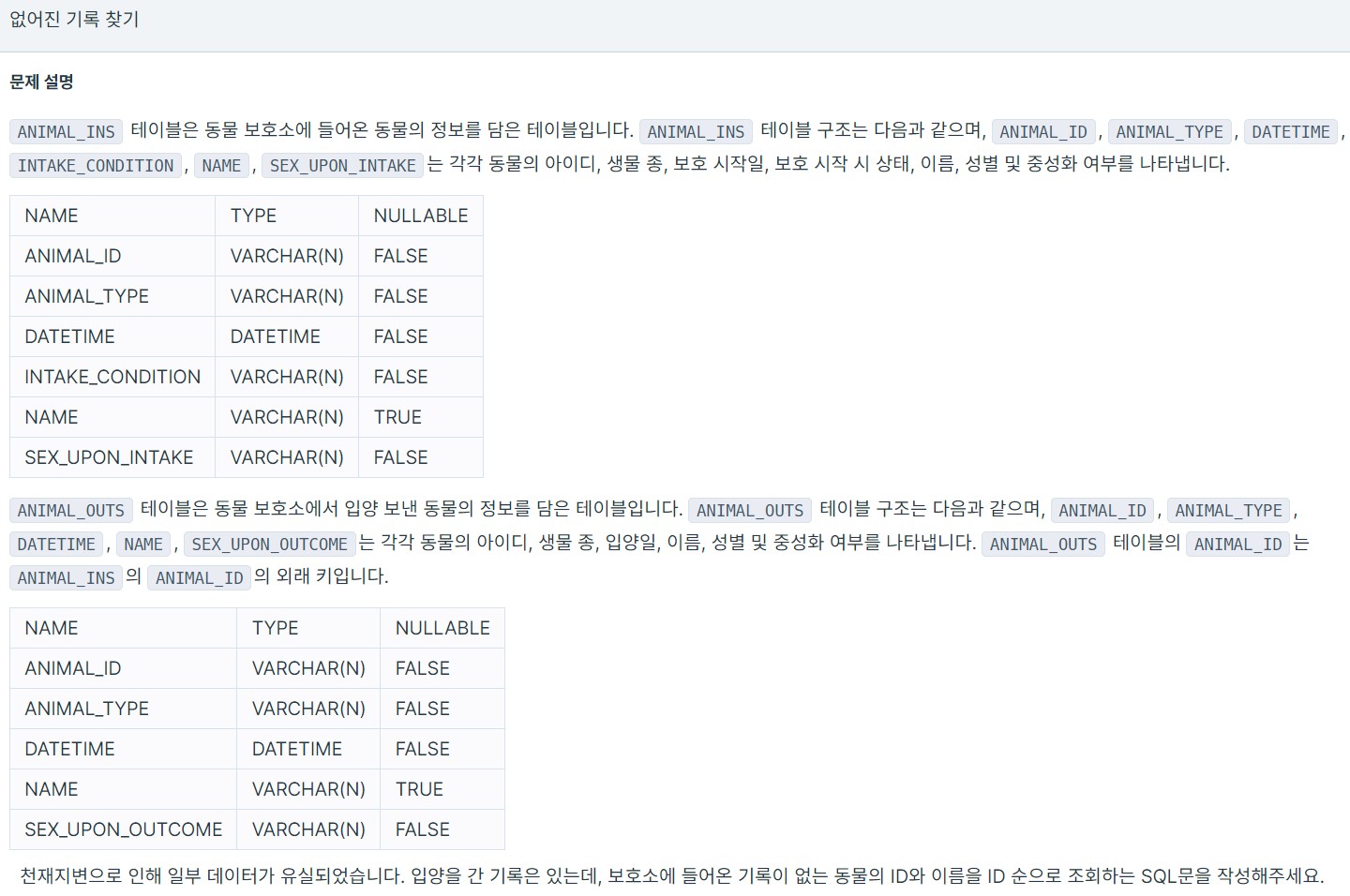
🙂 확인 사항
1. ANIMAL_INS, ANIMAL_OUTS 테이블
2. 입양을 간 기록은 있는데,
3. 보호소에 들어온 기록은 없는
4. 동물의 ID, 이름 조회
5. 동물 ID 기준 오름차순
😮 이 외의 풀이
|
1
2
3
4
5
6
7
8
9
10
|
SELECT ANIMAL_ID,
NAME
FROM ANIMAL_OUTS
WHERE ANIMAL_ID NOT IN (
SELECT ANIMAL_ID
FROM ANIMAL_INS
)
ORDER BY ANIMAL_ID
;
|
중첩 서브 query 사용
🔗 소스 코드
GitHub
'Computer > Algorithm_SQL' 카테고리의 다른 글
| [Algorithm_SQL] 있었는데요 없었습니다 (Success) (0) | 2023.10.13 |
|---|---|
| [Algorithm_SQL] 성분으로 구분한 아이스크림 총 주문량 (Success) (1) | 2023.10.10 |
| [Algorithm_SQL] 진료과별 총 예약 횟수 출력하기 (Success) (0) | 2023.10.08 |
| [Algorithm_SQL] 조건에 맞는 도서와 저자 리스트 출력하기 (Success) (1) | 2023.10.08 |
| [Algorithm_SQL] 재구매가 일어난 상품과 회원 리스트 구하기 (Success) (0) | 2023.10.06 |



