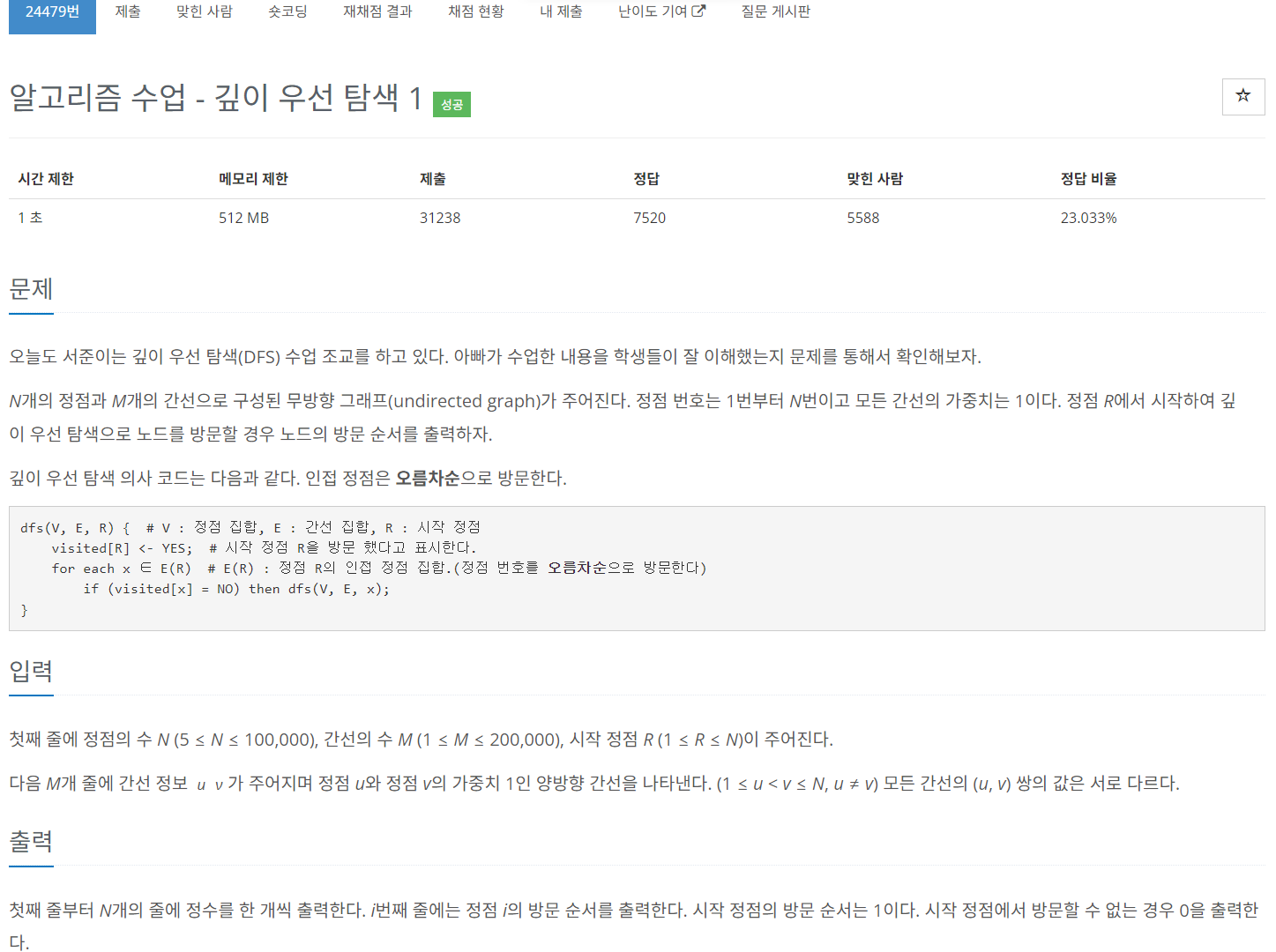
15652번: N과 M (4)
한 줄에 하나씩 문제의 조건을 만족하는 수열을 출력한다. 중복되는 수열을 여러 번 출력하면 안되며, 각 수열은 공백으로 구분해서 출력해야 한다. 수열은 사전 순으로 증가하는 순서로 출력해
www.acmicpc.net
☕Language: Java
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.StringTokenizer;
public class Main {
public static int[] arr;
public static StringBuilder sb = new StringBuilder();
public static int N, M;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
arr = new int[M];
dfs(1, 0);
br.close();
bw.write(sb.toString());
bw.flush();
bw.close();
}
public static void dfs(int idx, int depth) {
if (depth == M) {
for (int val : arr) {
sb.append(val).append(' ');
}
sb.append('\n');
return;
}
for (int i = idx; i <= N; i++) {
arr[depth] = i;
dfs(i ,depth + 1);
}
}
}
|
🤔 해설
1. arr = new int[M];
- 출력을 위한 arr 배열 생성
2. dfs(1, 0);
- dfs(방문 시작점, 배열 내 위치)
3. for (int i = idx; i <= N; i++) {
- i를 idx부터 시작함으로써 다음 depth에서 시작점보다 작은 값을 방문하지 않도록 함
4. arr[depth] = i;
- 배열 내 현재 위치에 값 입력
5. dfs(i, depth + 1);
- 깊은 노드로 이동
🔗 소스 코드
GitHub
'Computer > Algorithm_Java' 카테고리의 다른 글
| [Algorithm_Java] 문자열 내 p와 y의 개수 (Success) (1) | 2023.10.11 |
|---|---|
| [Algorithm_Java] 24480번 알고리즘 수업 - 깊이 우선 탐색 2 (Success) (0) | 2023.10.08 |
| [Algorithm_Java] 24479번 알고리즘 수업 - 깊이 우선 탐색 1 (Success) (0) | 2023.10.02 |
| [Algorithm_Java] 10872번 팩토리얼 (Success) (0) | 2023.10.01 |
| [BaekJoon] 11866번 요세푸스 문제 0 문제 풀이 (Success) (0) | 2023.09.30 |