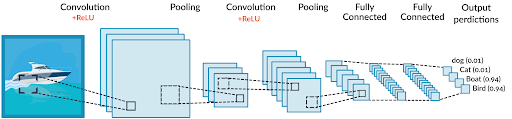
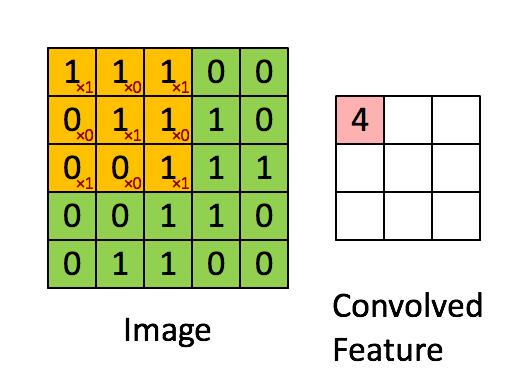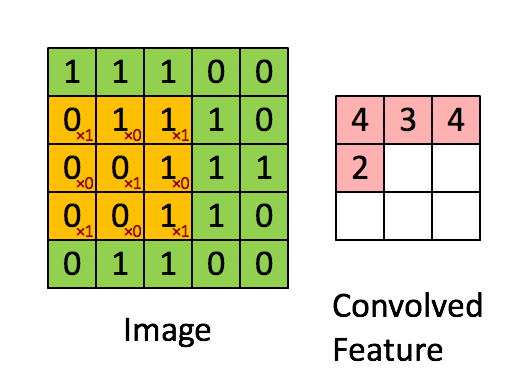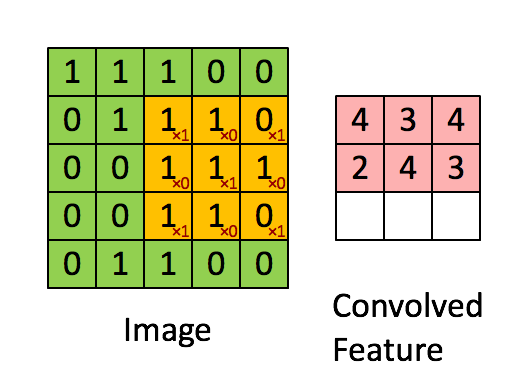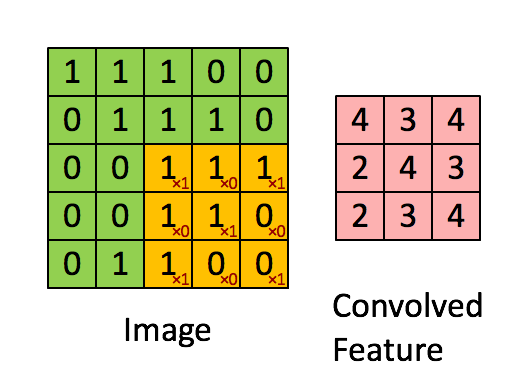
기본 환경: IDE: VS code, Language: Python
1. Save model and weights
# save_model_and_weights.py
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.callbacks import EarlyStopping
# Model save
path = './_save/' # ./ 현재(STUDY) dir
# path = '../_save/' # ../ 상위 dir
# path = 'c:/study/_save/' # 경로 대소문자 구분 X
# 1. Data
dataset = load_boston()
x = dataset.data # for training
y = dataset.target # for predict
x_train, x_test, y_train, y_test = train_test_split(
x, y,
train_size=0.7,
random_state=123
)
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
# 2. Model(Function)
input1 = Input(shape=(13,))
dense1 = Dense(64, activation='relu')(input1)
dense2 = Dense(32, activation='relu')(dense1)
output1 = Dense(1, activation='linear')(dense2)
model = Model(inputs=input1, outputs=output1)
# save model before training
model.save(path+'save_model1.h5')
# save weights before training(훈련이 되지 않은 가중치이므로 사용X)
model.save_weights(path +'save_weights1.h5')
# 3. compile and train
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
hist = model.fit(x_train, y_train,
epochs=512,
batch_size=16,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1)
# save model and weight after training
model.save(path+'save_model2.h5')
# save weights after training
model.save_weights(path+'save_weights2.h5')
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
def RMSE (y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE: ", RMSE(y_test, y_predict))
r2 = r2_score(y_test, y_predict)
print("R2: ", r2)
'''
Result
RMSE: 4.122959900727362
R2: 0.7896919500228364
'''* 훈련 전
- model.save(path+'save_model1.h5')
: model 및 weights 저장
: ⚠️ 훈련 전이므로 저장된 weights는 사용 X
- model.save_weights(path +'save_weights1.h5')
: weights 저장
: ⚠️ 훈련 전이므로 저장된 weights는 사용 X
** 훈련 후
- model.save(path+'save_model2.h5')
: model 및 weights 저장
model.save_weights(path+'save_weights2.h5')
: weights 저장
2. Load model and weights
# load_model_and_weights.py
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import Sequential, Model, load_model
from tensorflow.keras.layers import Dense, Input
# saved model path
path = './_save/' # ./ 현재(STUDY) dir
# path = '../_save/' # ../ 상위 dir
# path = 'c:/study/_save/' # 경로 대소문자 구분 X
# 1. Data
dataset = load_boston()
x = dataset.data # for training
y = dataset.target # for predict
x_train, x_test, y_train, y_test = train_test_split(
x, y,
train_size=0.7,
random_state=123
)
# scaler = StandardScaler()
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
# 2. Model(Function)
model = load_model(path+'save_model1.h5')
# save_model1.h5와 동일한 모델 구성 반환
# Model Construction 생략 가능
# 3. compile and train
model = load_model(path + 'save_model2.h5')
# save_model2.h5와 동일한 모델 구성 및 가중치 반환
# Model construction, compile and train 생략 가능
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
def RMSE (y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE: ", RMSE(y_test, y_predict))
r2 = r2_score(y_test, y_predict)
print("R2: ", r2)
'''
Result
RMSE: 4.122959900727362
R2: 0.7896919500228364
'''* 훈련 전
- model = load_model(path+'save_model1.h5')
: 저장된 model 및 weights 불러오기
⚠️ 훈련 전이므로 저장된 weights는 무의미
- model.load_weights(path + 'save_weights1.h5')
: 저장된 weights 불러오기
⚠️ weights를 가져왔으므로 fit 필요없으나, 훈련 전 저장된 weights 무의미
** 훈련 후
- model = load_model(path + 'save_model2.h5')
: 저장된 model 및 weights 불러오기
- model.load_weights(path + 'save_weights2.h5')
: 저장된 weights 불러오기
⚠️ RuntimeError: You must compile your model before training/testing. Use `model.compile(optimizer, loss)`.
⚠️ 가중치만 저장(Model 및 Compile 저장 X) -> 모델 구성 후 compile 필요
➕ weight만 따로 save 하는 이유
→ 큰 모델의 모델 및 가중치 저장 시, 파일의 크기가 큼(불러오기에서 문제가 발생할 가능성 존재)
→ 사이즈가 상대적으로 작은 훈련 결과 가중치만 저장하여 안전하게 불러오기
➕ 파일 확장자 .h5와 .hdf5
.h5 = .hdf5
HDF5는 Hierarchical Data Format이며 self-describing이 되는 고성능 데이터포맷 또는 DB
HDF5 파일을 생성하면 먼저 /라는 루트 그룹이 생성되고 그 하위에 트리 구조로 다른 그룹을 생성할 수 있음
그룹 하위에 다른 그룹이 있을 수도 있고, 데이터셋이 존재할 수도 있으며 운영체계의 디렉토리-파일 구조와 일치
소스 코드
참고 자료
'Naver Clould with BitCamp > Aartificial Intelligence' 카테고리의 다른 글
| RNN Model Construction (0) | 2023.01.27 |
|---|---|
| CNN Model Construction2 (0) | 2023.01.26 |
| CNN Model Construction (0) | 2023.01.24 |
| Data Preprocessing: StandardScaler, MinMaxScaler (0) | 2023.01.23 |
| Classification Model Construction (0) | 2023.01.23 |