반응형
Database
DBMS
- 데이터베이스를 관리하고 운영하는 소프트웨어
- 대부분의 DBMS는 테이블로 이뤄진 RDBMS(Relational DBMS) 형태로 사용
- 기능
- 데이터 정의(DDL): 테이블과 컬럼을 정의
- 데이터 조작(DML): 데이터의 CRUD 등을 수행
- 데이터 제어(DCL): 데이터 무결성(data integrity)을 지키도록 제어
RDBMS / NoSQL
- RDBMS:
- 정해진 스키마에 따라 데이터를 저장하기 때문에 명확한 데이터 구조 보장
- 시스템이 커질 수록 쿼리가 복잡해지고 성능이 저하되며, Scale-out이 어려움
- NoSQL:
- Key-Value 형태로 데이터를 자유롭게 관리할 수 있음
- 데이터 중복이 발생할 수 있음
- 데이터가 자주 변경이 이루어지는 시스템에서는 RDBMS를, 막대한 데이터를 저장해야 해서 DB를 Scale-out 해야 되는 시스템에서는 NoSQL을 사용
데이터베이스 무결성
- 개체 무결성: PK는 NULL 값이나 중복된 값을 가질 수 없음
- 참조 무결성: FK은 NULL이거나 참조 테이블의 PK값이어야 함
- 도메인 무결성: 속성값은 정의된 도메인에 속한 값이어야 함
- 키 무결성: 테이블은 최소 1개 이상의 키가 존재해야 함
정규화 정의 및 종류
- 데이터의 중복 방지, 무결성을 충족하기 위해 데이터베이스를 설계하는 방법
- 종류
- 제 1정규형: 테이블의 컬럼이 원자값(1개의 값)을 갖도록 분해
- 제 2정규형: 제 1정규형 만족 + 기본키가 아닌 속성이 기본키에 완전 함수 종속되도록 분해
- 제 3정규형: 제 2정규형 만족 + 이행적 함수 종속을 없애도록 분해
- 장점
- 불필요한 데이터 중복으로 인해 공간이 낭비를 줄임
- 삽입 이상, 갱신 이상, 삭제 이상 등 이상현상 제거
- 단점
- 릴레이션의 분해로 인해 릴레이션 간의 연산(JOIN 연산)이 많아져 질의에 대한 응답 시간이 느려질 수 있음
이상현상(Anomaly)
- 삽입 이상: 원하지 않는 자료가 삽입된다든지, key가 없어 삽입하지 못하는(불필요한 데이터를 추가해야 삽입할 수 있음) 문제점
- 삭제 이상: 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점
- 갱신 이상: 일부만 변경하여 데이터가 불일치하는 모순, 또는 중복되는 튜플이 존재하게 되는 문제점
반정규화
- 읽기작업이 많이 필요한 DB의 전반적인 성능을 향상시키기 사용
- 테이블이 단순해지고 관리 효율성이 증가
- 데이터의 일관성이나 무결성이 보장되지 않을 수 있음
Partitioning
- 큰 테이블이나 인덱스를 작은 파티션(Partition) 단위로 나누어 관리하는 기법
- 장점
- Full Scan에서 데이터 접근의 범위를 줄여 성능을 향상시킬 수 있음
- 큰 테이블들을 제거하여 관리를 쉽게 할 수 있음
- 파티션 별로 독립적으로 백업하고 복구할 수 있음
- 단점
- Join 비용
- 테이블과 인덱스를 별도로 파티셔닝 할 수 없음
JOIN
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
- Inner Join: 조인 키 컬럼 값이 양쪽 테이블에 공통적으로 존재하는 데이터만 추출
- Left Outer Join: Inner 조인값과 Left outer join 키워드 왼쪽에 명시된 테이블에만 존재하는 데이터를 추출
- Full Outer Join: 조인 키 컬럼 값이 양쪽 테이블 데이터 집합에서 공통적으로 존재하는 데이터와 한쪽 테이블에만 존재하는 데이터도 모두 추출
WHERE와 JOIN에서 ON의 차이
- WHERE: JOIN 결과를 WHERE 조건절로 필터링이 이뤄짐
- ON: JOIN 대상이 ON 조건으로 필터링 됨
WHERE와 HAVING의 차이
- where: 그룹화 또는 집계가 발생하기 전 개별 행을 필터링하는데 사용
- having: 그룹화 또는 집계가 발생한 후 그룹을 필터링하는데 사용
SELECT 쿼리의 수행 순서
FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY
View
- 데이터를 제한적으로 보여주기 위한 가상 테이블
- 장점
- view에 나타나지 않은 데이터를 간편히 보호할 수 있음
- 필요한 데이터만 뷰로 정의해서 처리할 수 있기 때문에 관리가 용이하고 명령문이 간단해짐
- 단점
- Alter를 사용하여 뷰의 정의를 변경할 수 없음
- 독립적인 인덱스를 가질 수 없음
Trigger
- 특정 테이블에서 INSERT, DELETE, UPDATE 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램
- 장점
- 데이터 무결성의 강화 (참조 무결성)
- 업무처리 자동화
- 단점
- 트리거를 과도하게 사용한다면 복잡한 상호 의존성이 생김
Index
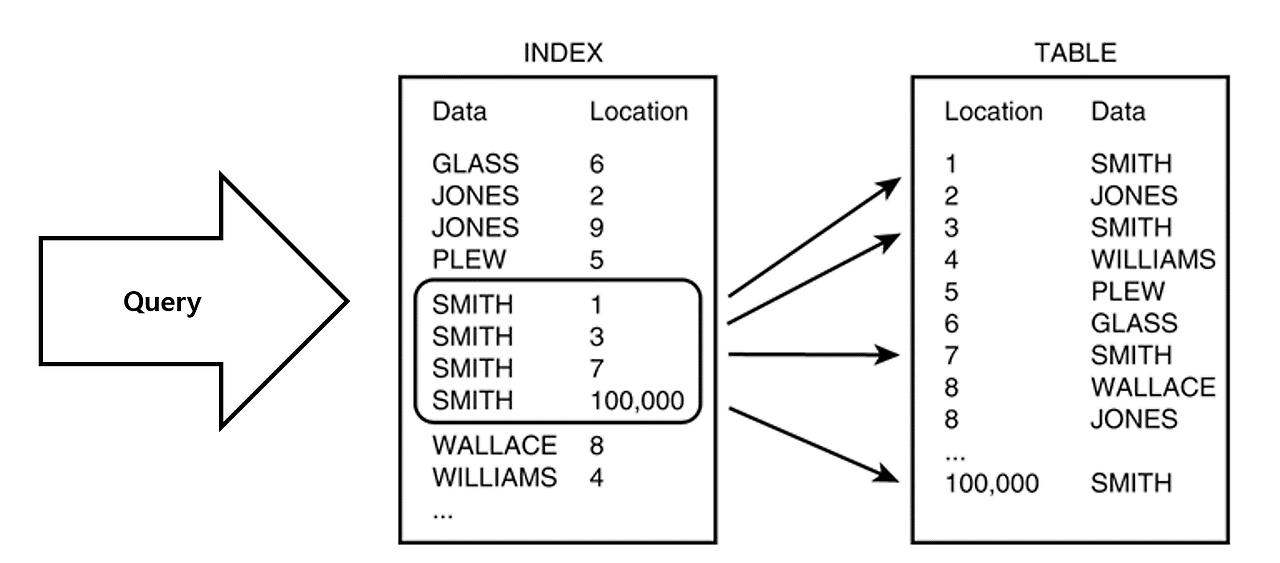
- 데이터에 대한 검색 성능의 속도를 높여주는 자료 구조
- 특정 컬럼에 인덱스를 생성하면 정렬된 데이터로 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장(Key-Value 타입)
- 새로운 값의 추가, 수정, 삭제할 경우, 재정렬과 2개의 컬럼을 수정해야하는 함
- 추가적인 메모리 공간을 필요하므로 자주 사용되는 조건에 Index를 설정하는 것이 좋음
Index 자료 구조

- B-Tree
- 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종
- 편향된 트리에서 leaf node까지 탐색한다면 모든 node를 방문하기 때문에 O(N)의 시간이 걸리게 되는 단점은 보완
- 최상의 경우 특정 key를 root node에서 찾을 수 있음
- Full scan 시, 모든 노드 탐색
- 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종

- B+Tree
- 오직 leaf node에만 데이터를 저장하고 leaf node가 아닌 node에는 자식 포인터만 저장
- 하나의 node에 더 많은 포인터를 가질 수 있기 때문에 트리의 높이가 더 낮아지므로 검색 속도를 높일 수 있음
- 반드시 특정 key에 접근하기 위해서 leaf node까지 가야함
- leaf node끼리는 Linked list로 연결
- Full scan 시, 리프 노드에서만 탐색
- 오직 leaf node에만 데이터를 저장하고 leaf node가 아닌 node에는 자식 포인터만 저장
- 해시 테이블
- key와 value를 한 쌍으로 데이터를 저장하는 자료구조
- 평균적으로 O(1)의 매우 빠른 시간만에 원하는 데이터를 탐색할 수 있음
- 데이터가 정렬되지 않은 상태로 등호 연산에 최적화되어있어, 부등호 연산이 많은 DB에서는 잘 사용되지 않음
트랜잭션
- 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 논리적 단위
- 특징
- 원자성: 하나의 트랜잭션에서 일부 연산만 실행되면 안됨
- 일관성: 트랜잭션 실행 전 후로 일관성을 갖춰야 함
- 독립성: 트랜잭션은 다른 트랜잭션과 독립적으로 수행되어야 함
- 영속성: 트랜잭션 결과는 영구적으로 반영되어야 함
- 상태
 - Active: 트랜잭션이 작업을 시작하여 실행 중인 상태 - Failed: 트랜잭션에 오류가 발생하여 실행이 중단된 상태 - Aborted: 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태 - Partially Committed: 최종 결과를 데이터베이스에 아직 반영하지 않은 상태 - Committed: 트랜잭션이 성공적으로 종료되어 commit 연산을 실행한 후의 상태
- Active: 트랜잭션이 작업을 시작하여 실행 중인 상태 - Failed: 트랜잭션에 오류가 발생하여 실행이 중단된 상태 - Aborted: 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태 - Partially Committed: 최종 결과를 데이터베이스에 아직 반영하지 않은 상태 - Committed: 트랜잭션이 성공적으로 종료되어 commit 연산을 실행한 후의 상태 - 연산
- Commit: TRANSACTION(INSERT, UPDATE, DELETE)작업 내용을 실제 DB에 저장
- Rollback: TRANSACTION(INSERT, UPDATE, DELETE)작업 내용을 취소
JDBC, ODBC 차이
- JDBC
- Java가 Database를 사용할 수 있도록 연결
- 자바 어플리케이션의 요청을 각 DBMS가 이해할 수 있도록 변환
- ODBC
- 언어에 상관없이 사용 가능
- 응용프로그램에서 데이터에 접근할 때 사용
DELETE, TRUNCATE, DROP의 차이
- DELETE
- 데이터는 지우지만 테이블 용량은 줄어들지 않음
- 원하는 데이터만 골라서 지울 수 있음
- 삭제 후 되돌릴 수 있음
- TRUNCATE
- 전체 데이터를 한번에 삭제하는 방식
- 테이블 용량이 줄어들고 인덱스 등도 삭제
- 삭제 후 되돌릴 수 없음
- DROP
- 테이블 자체를 완전히 삭제하는 방식
- 삭제 후 되돌릴 수 없음
SQL Injection
- 악의적인 의도로 SQL 구문을 삽입하여, 데이터베이스를 비정상적으로 조작하는 코드 인젝션 공격 기법
- 해결 방안
- 저장 프로시저 사용하여 Query에 미리 형식을 지정하여 지정된 형식의 데이터가 아니면 Query가 실행되지 않도록 함
기타 용어
Schema: 데이터베이스에 저장되는 데이터 구조와 제약조건을 정하는 것
Sequence: 기본키가 유일한 값을 갖도록 순번을 자동 생성해주는 데이터베이스 객체
📚 참고 자료
https://coding-factory.tistory.com/746
https://rebro.kr/167
https://coding-factory.tistory.com/224
https://luv-n-interest.tistory.com/1466
https://dkswnkk.tistory.com/555
반응형
'Computer > CS_Knowledge' 카테고리의 다른 글
| [CS] Design Pattern (0) | 2023.08.04 |
|---|---|
| [CS] Network (0) | 2023.07.12 |
| [CS] Operating System (0) | 2023.07.12 |
| [CS] Spring (0) | 2023.07.06 |
| [CS] Java (0) | 2023.07.06 |