기본 환경: IDE: VS code, Language: Python
Machine Learning
1. Supervised Learning
: 훈련 데이터에 레이블(학습에서의 정답)이 있는 경우
1.1. Regression: 회귀
: 예측하려는 값이 연속값일 경우, 회귀 모델 사용
1.2. Classification: 분류
: 예측하려는 값이 이산값(한정된 값)일 경우, 분류 모델 사용
1.2.1. Binary Classification
1.2.2. Multi Classification
2. Unsupervised Learning
: 훈련 데이터에 레이블(학습에서의 정답)이 없는 경우
2.1. Clustering: 군집화
2.2. Transform: 변환
2.3. Association: 연관
지도학습 분류, 모델 구축
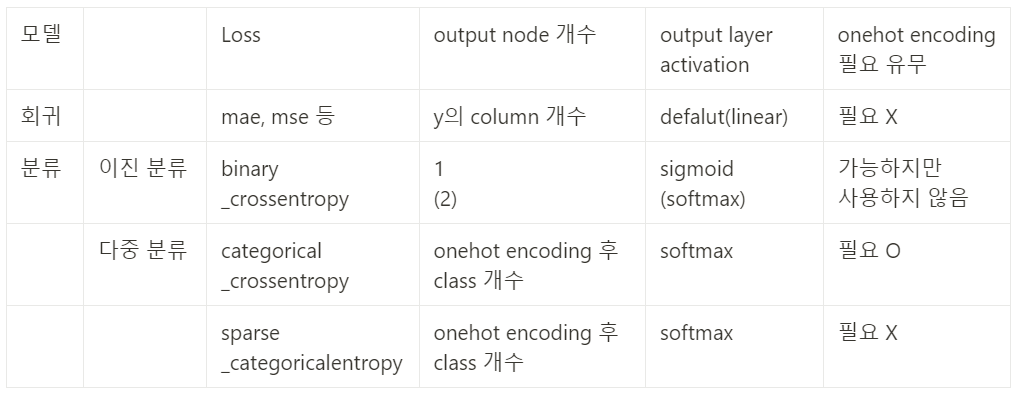
⭐ 이진분류(binary_crossentropy)
# sigmoid_acc_cancer.py
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 1. Data
datasets = load_breast_cancer()
x = datasets['data'] # (569, 30) for training
y = datasets['target'] # (569, ) for predict
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
shuffle= True,
random_state = 123
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, activation='linear', input_shape=(30,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 3. Compile and train
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
hist = model.fit(x_train, y_train,
epochs=100, batch_size=16,
validation_split=0.2,
verbose=1)
# 4. evaluate and predict
loss, accuracy = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
pred_class = np.where(y_predict >= 0.5, 1, 0)
acc = accuracy_score(y_test, pred_class)
print("accuarcy_score: ", acc)
'''
Result
accuarcy_score: 0.956140350877193
'''
⭐ 다중분류(multi_crossentropy)
⭐ categorical_crossentropy
# categorical_crossentropy_wine.py
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 1. Data
datasets = load_wine()
x = datasets.data
y = datasets['target']
print(x.shape, y.shape) # (178, 13) (178,)
# print(y)를 통해서 012로 이뤄져있으면 분류
# (문제) 데이터가 많을 때 판단이 어려울수 있음
# (해결) np.unique
print(np.unique(y, return_counts=True))
# [0 1 2] 중복값을 제외한 y 값, return_counts를 통해 element의 개수 반환
# output_dim = 1, y_class = 3
y=to_categorical(y)
x_train, x_test, y_train, y_test = train_test_split(
x,y,
shuffle=True,
random_state=333,
test_size=0.2,
stratify=y
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(13, )))
model.add(Dense(64, activation='sigmoid'))
model.add(Dense(32,activation='relu'))
model.add(Dense(16,activation='linear'))
model.add(Dense(3,activation='softmax'))
# 3. Compile and train
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs=256, batch_size=16,
validation_split=0.2,
verbose=1)
# 4. evaluate and predict
loss, accuracy = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
y_predict = np.argmax(y_predict, axis=1)
y_test = np.argmax(y_test, axis=1)
acc = accuracy_score(y_test, y_predict)
print(acc)
'''
Result
acc: 0.3888888888888889
'''
⭐ sparse_categorical_crossentropy
# sparse_categorical_crossentropy_iris.py
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# iris 꽃잎, 꽃받침의 길이 넓이 등을 통해 어떤 꽃인지 맞추는 data
from sklearn.metrics import accuracy_score
# 1. Data
datasets = load_iris()
# print(datasets.DESCR) # pandas.describe
# attribute = column, feature, 열, 특성
# x_column(input_dim=4): sepal (length, width), petal (length, width) (cm)
# output_dim=1(3 class(종류): Iris-Setosa, Iris-Versicolour, Iris-Virginica)
# print(datasets.feature_names) # pandas.columns
x = datasets.data # (150, 4)
y = datasets['target'] # shape(150,), [0, 1, 2]
'''
# sklearn: one_hot encoding
onehot_encoder=OneHotEncoder(sparse=False)
reshaped=y.reshape(len(y), 1)
onehot=onehot_encoder.fit_transform(reshaped)
print(onehot)
[[1. 0. 0.]...[0. 0. 1.]]
print(onehot.shape) (150, 3)
# keras: to_categorical
to_cat=to_categorical(y)
print(to_cat)
[[1. 0. 0.]...[0. 0. 1.]]
print(to_cat.shape) (150, 3)
# pandas: get_dummies
print(pd.get_dummies(y))
[150 rows x 3 columns]
'''
x_train, x_test, y_train, y_test = train_test_split(
x,y,
shuffle=True, # Non-shuffle: y_train, y_test 자료의 치우침이 발생
random_state=333,
test_size=0.2,
stratify=y # 원본 자료 내 비율 유지 - 분류형 데이터에서만 사용 가능
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(4, ))) # input_dim = 4
model.add(Dense(64, activation='sigmoid'))
model.add(Dense(32,activation='relu'))
model.add(Dense(16,activation='linear'))
model.add(Dense(3,activation='softmax'))
# 이진분류: output_dim = 1(col), activatoin = 'sigmoid', loss = 'binarycrossentropy'
# 다중분류: output_dim = 3(class), activatoin = 'softmax', loss = 'categorical_crossentropy'
# y_col: 1, y_class(종류): 3
# class의 number: 0, 1, 2 -> 동등한 대상임에도 불구하고 value의 차이가 발생
# One_Hot encoding 실행: 10진 정수 형식을 특수한 2진 binary 형식으로 변환
# 3. Compile and train
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs=256, batch_size=32,
validation_split=0.2,
verbose=1)
# 4. evaluate and predict
loss, accuracy = model.evaluate(x_test, y_test)
'''
Result
print(y_test[:5])
y_predict = model.predict(x_test[:5]) # slicing
print(y_predict)
y_test
[[1. 0. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]
[0. 1. 0.]]
y_predict
[[9.9925297e-01 7.4696867e-04 2.5099497e-13] 0
[4.1013454e-10 2.7499644e-03 9.9725002e-01] 2
[9.9945968e-01 5.4027850e-04 1.0871933e-13] 0
[2.5293427e-06 6.0845017e-01 3.9154729e-01] 1
[6.0919424e-06 8.0725497e-01 1.9273894e-01]] 1
y_predict를 통해서 y_test를 추론할 수 있음
'''
y_predict = model.predict(x_test)
# y_predict: y_test 값을 확률로 반환(class 확률 합=1)
y_predict = np.argmax(y_predict, axis=1)
# arg 중 가장 큰 확률을 뽑아 위치값을 반환(0, 1, 2...)
# y_test = np.argmax(y_test, axis=1)
# (numpy.AxisError: axis 1 is out of bounds for array of dimension 1)
# onehot encoding type이 아니라면 argmax 사용이 의미 없음
acc = accuracy_score(y_test, y_predict)
print(acc)
'''
Summary
y_test: [1. 0. 0.] 타입
y_predict: 실수 타입
(타입 불일치 오류) ValueError: Classification metrics can't handle a mix of multilabel-indicator and continuous-multioutput targets
(해결) y_predict = np.argmax(y_predict, axis=1)
argmax를 사용해서 arg 중 가장 큰 값을 뽑아 위치값을 반환
(타입 불일치 오류) ValueError: Classification metrics can't handle a mix of multilabel-indicator and continuous-multioutput targets
(최종 결과)
[0 2 0 2 1 1 0 2 0 2 2 2 2 0 0 0 2 0 2 1 0 2 1 1 0 2 1 1 1 2]
[0 2 0 1 1 1 0 2 0 2 2 2 2 0 0 0 2 0 2 1 0 2 1 1 0 2 1 1 1 1]
를 기준으로 accuracy 판단
'''
소스 코드
참고 자료
📑 회귀 VS 분류
📑 [비전공자를 위한 딥러닝] 1.4 - 회귀/분류, 지도학습/비지도학습
📑 Classification and One-Hot Encoding
📹 인공지능의 학습법과 응용 사례 (머신러닝, 딥러닝, GAN) [안될과학-긴급과학 X 삼성SDS ]
'Naver Clould with BitCamp > Aartificial Intelligence' 카테고리의 다른 글
| CNN Model Construction (0) | 2023.01.24 |
|---|---|
| Data Preprocessing: StandardScaler, MinMaxScaler (0) | 2023.01.23 |
| Pandas pkg and Numpy pkg (1) | 2023.01.23 |
| Classification and One-Hot Encoding (0) | 2023.01.23 |
| Handling Overfitting: EarlyStopping (0) | 2023.01.22 |

