
기본 환경: IDE: VS code, Language: Python
⭐ plt.plot 형태에 따른 모델의 훈련 과정 확인
# plot_boston.py
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 1. Data
datasets = load_boston()
x = datasets.data # (506, 13)
y = datasets.target # (506, )
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
shuffle= True,
random_state = 333
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, input_shape=(13,)))
model.add(Dense(32))
model.add(Dense(16))
model.add(Dense(1))
# 3. Compile and train
model.compile(loss='mse', optimizer='adam')
hist = model.fit(x_train, y_train,
epochs=256,
batch_size=32,
validation_split=0.2,
verbose=0)
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
print(hist.history)
'''
fit의 history는 loss 결과값을 dictionary(key-value(list)) 형태로 반환
key: 'loss', 'val_loss' / value = list[] 형태의 epochs의 loss, val_loss 값들의 집합
{'loss': [25004.84765625, 1219.100830078125, 160.86378479003906, 82.83763122558594, 73.0763931274414, 71.3211669921875, 71.86249542236328, 70.77513885498047, 68.52639770507812, 68.08159637451172],
'val_loss': [2787.144775390625, 272.2074279785156, 78.57952880859375, 58.332862854003906, 55.535221099853516, 54.82481002807617, 54.39116668701172, 56.427764892578125, 59.47801971435547, 55.58904266357422]}
'''
print(hist.history['loss']) # key -> value 반환
print(hist.history['val_loss'])
import matplotlib.pyplot as plt
# (epochs, loss)의 산점도 및 그래프를 작성할 수 있음
plt.figure(figsize=(9, 6)) # 그래프 사이즈 설정: figsize=(가로 inch, 세로 inch)
plt.plot(hist.history['loss'], c='red', marker='.', label='loss') # x 추론 가능 시, x 생략 가능
plt.plot(hist.history['val_loss'], c='blue', marker='.', label='val_loss')
# c: color, marker: graph 형태, label: graph name
plt.title('Boston loss') # graph name
plt.xlabel('epochs') # x축 이름
plt.ylabel('loss') # x축 이름
plt.grid() # 격자 표시
plt.legend(loc='upper right') # 선 이름(label) 표시, location 미 지정 시 그래프와 안 겹치게 생성
plt.show()
'''
Result
loss 26.94292640686035
plt.show()
문제: min(loss)가 아닌 훈련값(Overfit)이 존재
해결: min(loss)가 아닌 지점에서 훈련 중지
'''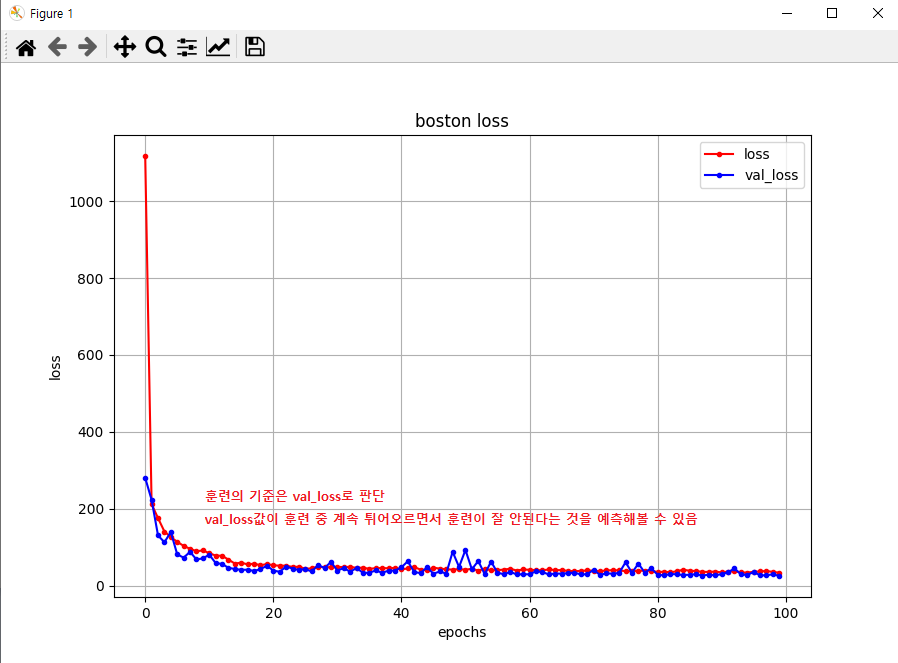
⚠️ plot graph를 통해 val_loss가 높아지는 비효율적인 훈련이 이뤄지는 구간을 확인
⭐ EarlyStopping을 사용하여, 성능에 안 좋아질 경우에 훈련을 자동으로 종료
⭐ EarlyStopping Mechanism
→ 매 훈련마다 loss 확인
→ min loss가 나오지 않더라도 넘어갈 수 있는 횟수 지정
예: 5번까지 min loss가 나오지 않더라도 training을 지속
(⭐ 최적의 early stopping timing을 찾는 것이 중요)
→ 횟수 내에 min loss가 안 나오면 훈련(fit) 수행 중지
# earlyStopping_boston.py
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 1. Data
datasets = load_boston()
x = datasets.data # (506, 13)
y = datasets.target # (506, )
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
shuffle= True,
random_state = 333
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, input_shape=(13,)))
model.add(Dense(32))
model.add(Dense(16))
model.add(Dense(1))
# 3. Compile and train
model.compile(loss='mse', optimizer='adam')
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=16, restore_best_weights=True, verbose=1)
# monitor: val_loss로 earlyStopping 지점 확인
# mode: accuracy-max, loss-min, max인지 min인지 모를 때, auto 사용
# patience=5: 갱신이 되지 않더라도 16번 참음
# restore_best_weight: 훈련이 끊긴 지점이 아닌 최적의 weight 지점을 저장
# verbose를 통해 earlyStopping 지점을 확인할 수 있음: Restoring model weights from the end of the best epoch.
hist = model.fit(x_train, y_train,
epochs=256,
batch_size=16,
validation_split=0.2,
callbacks=[earlyStopping],
# 정지된 지점-5: min(val_loss)
# 문제: 5번 인내 후, 최소가 아닌 val_loss 지점에서의 weight가 아닌 끊긴 지점에서의 weight가 반환
# 해결: restore_best_weights="True"를 통해 최적의 weight 지점을 반환
# restore_best_weights="False" Defualt
# 최적의 weight로 predict 수행(false일 경우, epoch가 마무리된 weight를 기준으로 predict 수행)
verbose=1
)
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
'''
Result
Epoch 79/256
21/21 [==============================] - 0s 6ms/step - loss: 66.6039 - val_loss: 83.2419
Restoring model weights from the end of the best epoch: 63.
Epoch 00079: early stopping
'''
➕ plt에 한글 사용 방법
# matplotlib 한글 설정
from matplotlib import font_manager, rc
font_path = "C:\Windows\Fonts\malgun.ttf"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
➕ epoch 당 loss 값의 산점도(Scatter)
# scatter_boston.py
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
# 1. Data
datasets = load_boston()
x = datasets.data # (506, 13)
y = datasets.target # (506, )
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
shuffle= True,
random_state = 123
)
# 2. Model Construction
model = Sequential()
model.add(Dense(64, input_shape=(13,)))
model.add(Dense(32))
model.add(Dense(16))
model.add(Dense(1))
# 3. Compile and train
model.compile(loss='mse', optimizer='adam')
hist = model.fit(x_train, y_train,
epochs=256,
batch_size=16,
validation_split=0.2,
verbose=0)
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
import matplotlib.pyplot as plt
x_len = np.arange(len(hist.history['loss']))
plt.scatter(x_len, hist.history['loss'])
# len(hist.history['loss']): fit(x_train)의 loss의 개수 = epochs
# 산점도(x 생략 불가)
plt.show() # 작성한 plt show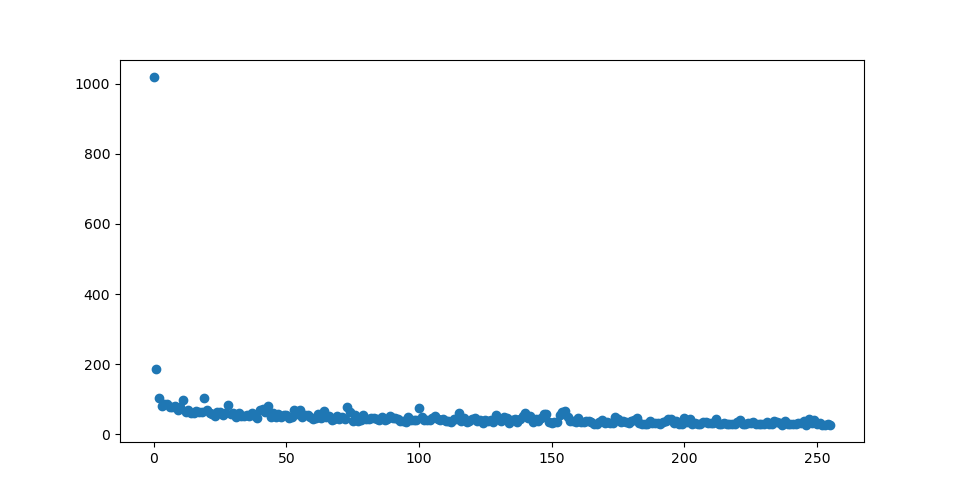
➕ Model Check Point
⭐ EarlyStopping: 최적의 weight가 갱신이 안되면 훈련을 끊어주는 역할
⭐ ModelCheckPoint: 최적의 weight가 갱신될 때마다 저장해주는 역할
1. Save the Model Check Point
# save_ModelCheckPoint.py
import numpy as np
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
path = './_save/'
# 1. Data
dataset = load_boston()
x = dataset.data # for training
y = dataset.target # for predict
x_train, x_test, y_train, y_test = train_test_split(
x, y,
train_size=0.7,
random_state=123
)
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
# 2. Model(Function)
input1 = Input(shape=(13,))
dense1 = Dense(64, activation='relu')(input1)
dense2 = Dense(64, activation='sigmoid')(dense1)
dense3 = Dense(32, activation='relu')(dense2)
dense4 = Dense(32, activation='linear')(dense3)
output1 = Dense(1, activation='linear')(dense4)
model = Model(inputs=input1, outputs=output1)
# 3. compile and train
model.compile(loss='mse', optimizer='adam', metrics=['mae'])
earlyStopping = EarlyStopping(monitor='val_loss', mode='min', patience=32, restore_best_weights=True, verbose=1)
modelCheckPoint = ModelCheckpoint(monitor='val_loss', mode='auto', verbose=1,
save_best_only=True,
filepath=path+'MCP/save_ModelCheckPoint.hdf5') # MCP/ = MCP파일 하단
# 가중치 및 모델 저장 확장자: h5
# ModelCheckPoint 저장 확장자: hdf5
model.fit(x_train, y_train,
epochs=512,
batch_size=16,
validation_split=0.2,
callbacks=[earlyStopping, modelCheckPoint],
verbose=1)
'''
epochs=512
Epoch 00001: val_loss improved from inf to 481.11652, saving model to ./_save/MCP\save_ModelCheckPoint1.hdf5
-> 처음 훈련은 최상의 결과값이므로 저장
Epoch 00002: val_loss improved from 481.11652 to 273.11346, saving model to ./_save/MCP\save_ModelCheckPoint1.hdf5
-> 2번째 훈련 개선 -> 덮어쓰기
-> 반복
Epoch 00024: val_loss did not improve from 10.37429
-> 개선되지 않을 경우 저장 X
-> 개선되지 않은 결과가 20번 반복될 경우, EarlyStopping = 가장 성능이 좋은 ModelCheckPoint 지점
Epoch 67/512
14/18 [======================>.......] - ETA: 0s - loss: 5.7881 - mae: 1.6581
Restoring model weights from the end of the best epoch: 35.
MCP 저장
MSE: 4.433804789382322
R2: 0.7567847452094035
EarlyStopping: 최적의 weight가 갱신이 안되면 훈련을 끊어주는 역할
ModelCheckPoint: 최적의 weight가 갱신될 때마다 저장해주는 역할
'''
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
def RMSE (y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE: ", RMSE(y_test, y_predict))
r2 = r2_score(y_test, y_predict)
print("R2: ", r2)
'''
Result
MSE: 4.433804789382322
R2: 0.7567847452094035
'''
2. Load the Model Check Point
# load_ModelCheckPoint.py
import numpy as np
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import Sequential, Model, load_model
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
path = './_save/'
# 1. Data
dataset = load_boston()
x = dataset.data # for training
y = dataset.target # for predict
x_train, x_test, y_train, y_test = train_test_split(
x, y,
train_size=0.7,
random_state=123
)
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
# 2. Model(Function)
# 3. compile and train
model = load_model(path+'MCP/save_ModelCheckPoint.hdf5') # load_model로 모델과 가중치 불러오기
'''
MCP 저장
MSE: 4.433804789382322
R2: 0.7567847452094035
'''
# 4. evaluate and predict
loss = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
def RMSE (y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print("RMSE: ", RMSE(y_test, y_predict))
r2 = r2_score(y_test, y_predict)
print("R2: ", r2)
'''
Result
RMSE: 4.433804789382322
R2: 0.7567847452094035
'''⭐ Training Result 비교
1. restore_best_weights = True
(Break 지점이 아닌 최적의 weight를 저장)
load_model(EarlyStopping)
load_model(ModelCheckPoint)
→ 연산 결과 모두 동일
2. restore_best_weights = False
load_model(EarlyStropping)
load_model(ModelCheckPoint)
→ 연산 결과 ModelCheckPoint 결과가 더 우수함
(restore_best_weights = False, 최적 weight에서 연산을 멈추지 않고 patience만큼 연산이 밀린 후 연산이 멈추므로)
⚠️ 단, train data set에서 최적의 weight 지점이 test data set에서는 아닐 수 있듯, 밀려난 지점이 test data set에서는 더 우수한 weight를 뽑아낼 수 있음
소스 코드
참고 자료
📑 [python] matplotlib로 플롯 그릴 때 한글 깨짐 문제 해결 방법 (윈도우)
📑 Keras - Epoch와 오차(Loss)간 관게를 그래프로 확인하기
'Naver Clould with BitCamp > Aartificial Intelligence' 카테고리의 다른 글
| Pandas pkg and Numpy pkg (1) | 2023.01.23 |
|---|---|
| Classification and One-Hot Encoding (0) | 2023.01.23 |
| Validation Data (0) | 2023.01.22 |
| Activation Function (0) | 2023.01.22 |
| Pandas Package and Missing Value Handling (0) | 2023.01.21 |